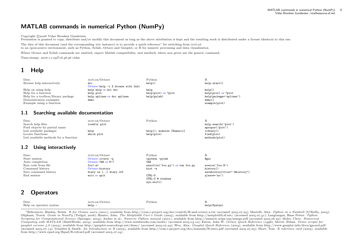
Python for Data Science Cheat Sheet - Pyspark Rdd

The Python for Data Science Cheat Sheet - Pyspark RDD is a reference guide that provides quick and concise code snippets and explanations for using PySpark's Resilient Distributed Datasets (RDD) in data science applications. It helps users easily work with large-scale data sets and perform various data operations using PySpark.
FAQ
Q: What is a Python for Data Science Cheat Sheet?
A: A cheat sheet is a quick reference guide that provides a summary of concepts and commands for a particular topic, in this case, Python for Data Science.
Q: What is PySpark RDD?
A: PySpark RDD stands for Resilient Distributed Datasets, which are a fundamental data structure in Spark. RDDs are immutable distributed collections of objects that can be processed in parallel.
Q: What is PySpark?
A: PySpark is the Python library for Apache Spark, a powerful open-source framework for Big Data processing and analytics.
Q: What are some commonly used functions with PySpark RDD?
A: Some commonly used functions with PySpark RDD include map, filter, reduce, collect, count, take, and join.
Q: How can I create a PySpark RDD?
A: You can create a PySpark RDD by parallelizing an existing collection in Python or by loading data from external storage systems like Hadoop HDFS.
Q: What are the advantages of using PySpark RDD?
A: Some advantages of using PySpark RDD are fault tolerance, parallel processing, in-memory computation, and compatibility with other Spark components.